Explore digital, technology, cloud, RPA, software, platforms and much more
Visual ChatGPT – multimodal AI for visual content
by Murukesh Jayaraj|
The pace of progress in AI has been unprecedented in recent months, with innovations occurring so quickly that they have surpassed the typical ‘hype cycle’ associated with the technology.
Microsoft recently unveiled a new model called ‘Visual ChatGPT’, which incorporates different types of Visual Foundation Models (VFMs). The model allows interaction with ChatGPT beyond natural language wherein you can generate, create, modify images using prompts.
It is said that Visual Foundation Models (VFMs) has shown enormous potential in computer vision. However, VFMs are less adaptable than conversational language models in human-machine interaction due to the constraints imposed by the nature of task definition and the predefined input-output formats. Now that by training the LLMs as a multimodal conversational model, it becomes a natural solution that can be leveraged as a system similar to ChatGPT, but with the ability to comprehend and create visual content.
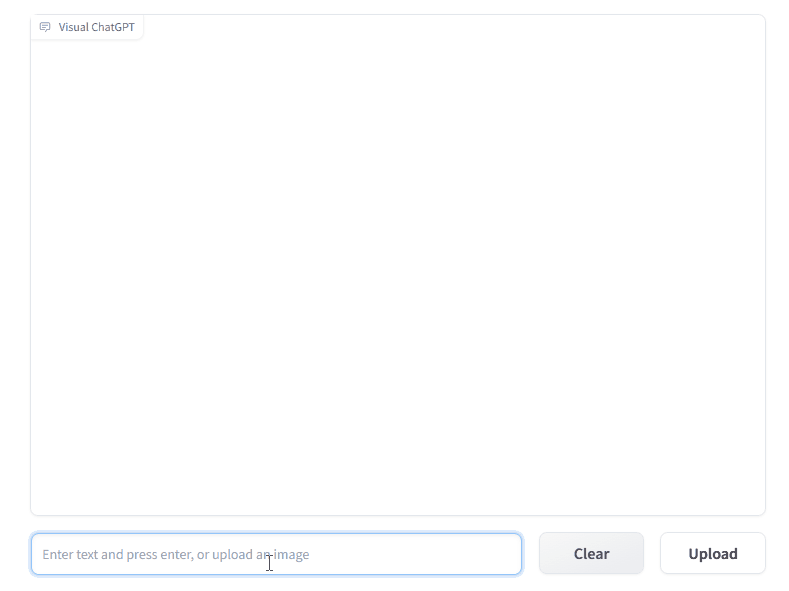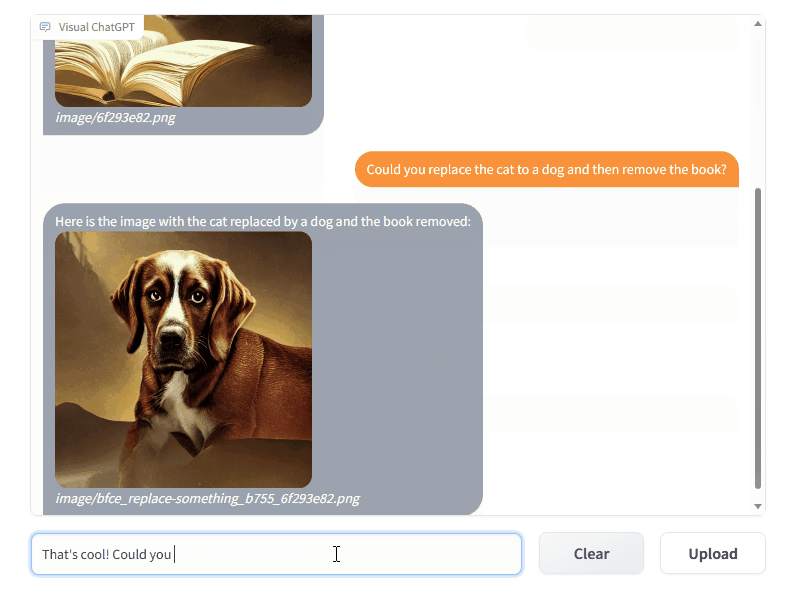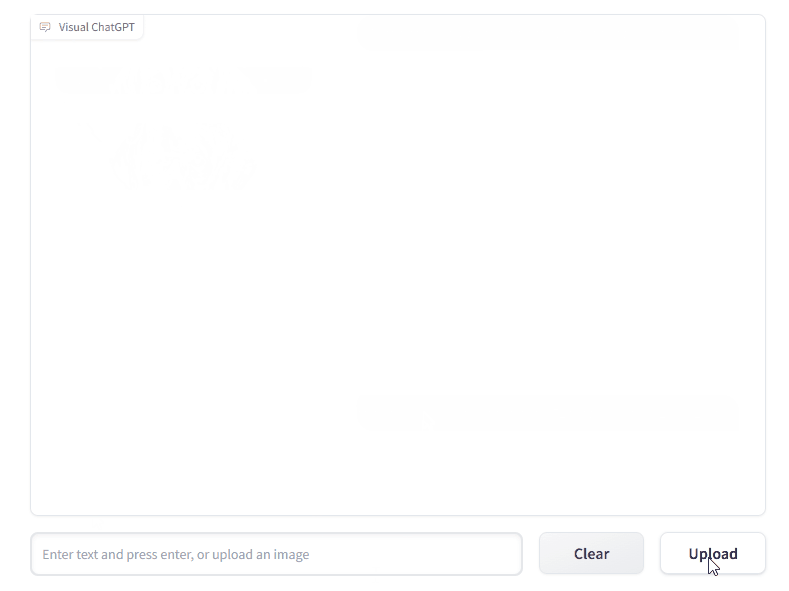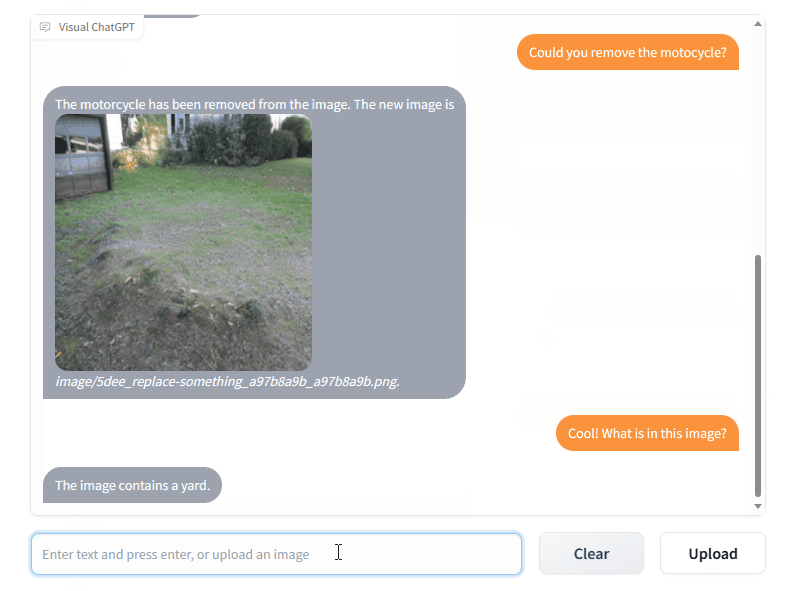
Thereby, this feature will allow users to interact with ChatGPT using images rather than solely relying on text. Additionally, users can ask for complex image-related inquiries or seek visual editing by utilizing a multi-step approach involving various AI models. Users can also request feedback and corrections on the outcomes.
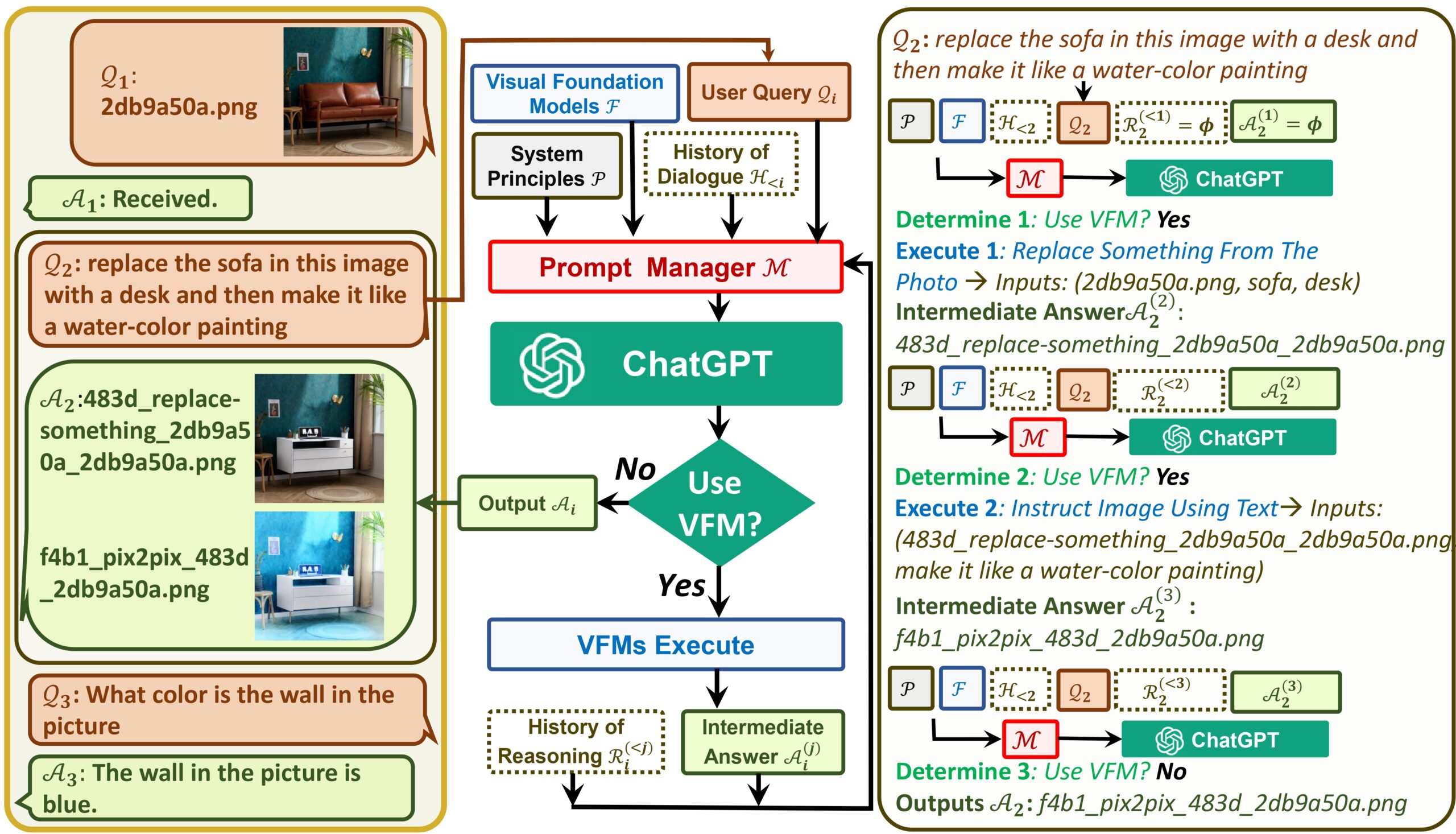
Here again, the interaction happens via prompting. The Prompt Manager allows ChatGPT to utilize VFMs efficiently and receive feedback from them iteratively until the users’ demands are satisfied, or a conclusion is reached. This Prompt Manager acts as a bridge between ChatGPT and VFMs and includes the following features.
Specifies the input and output formats and informs ChatGPT on the capabilities of each VFM
Handles the histories, priorities, and conflicts of various Visual Foundation Models
Turns various visual information, such as PNG images, depth images, and mask matrix, into language format to aid ChatGPT in understanding.
Here below is how the system architecture looks like – published on the Microsoft GitHub page.
Visual ChatGPT Demo Image
But the question is, how does it perform to meet human expectations? Researchers say, the inconsistency of the Prompt and failure of VFMs are causing worries since they lead to less-than-satisfactory generation results. There is a need for a self-correcting module to verify that execution results are consistent with human intentions and to make the needed edits. This possibly increases the the model’s inference time due to its tendency to constantly course-correct itself. But in the AI race, it shall not be long to come up with solution.
Thanks for Reading. Stay Tuned!
Look forward to connecting with you!
Finally, “subscribe” to my newsletter, so that you get notified every time when I publish.